Webサイトから画像を一括ダウンロードする方法

元記事:https://www.octoparse.jp/blog/how-to-scrape-and-bulk-download-images-from-any-website/
1. Webサイトから画像を取得する方法
Webサイトから全ての画像を一括で保存したいとき、1枚ずつ保存するのは非常に面倒です。これは非常に退屈なプロセスであり、仕事の効率を低下させます。
実際、Webスクレイピングツールは、この作業を自動化するの最適な選択肢です。Webページを無限にクリックする代わりに、5分以内にタスクを設定するだけで、クローラーがすべての画像URLを取得してくれます。画像を一括でダウンロードツールにコピーすると、わずか10分で完成させます。
2. Webスクレイピングツールをダウンロード
まずは「Webスクレイピングツールにオススメの10選」という記事から自分に合ったWebスクレイピングツールを探しましょう!今回は、上記の記事から紹介されたOctoparseを例として紹介します。
なお、これは簡単なガイドであり、プログラミングの経験は必要ありません。心配しないでください。
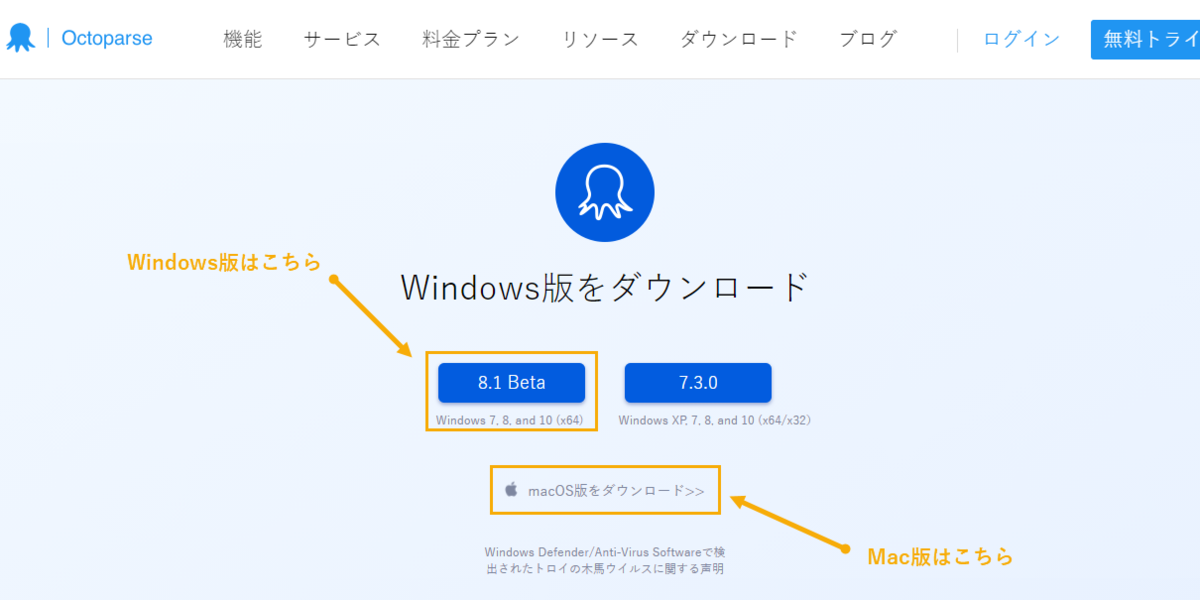
注:Octoparseは無料プランを提供しています。このガイドに記載されている機能にお金を払う必要はありません。
3. 2つのステップだけで、すべての画像URLを取得
ステップ1: タスクを作成する
1)Octoparseを起動します。スクレイピングしたいWebページのURLを入力します。「抽出開始」 ボタンをクリックして進みます。

もうすぐホワイトデーですので、今回は楽天市場上のチョコレートの画像を例にしてみましょう。
サンプルURL: https://search.rakuten.co.jp/search/mall/チョコレート/
(このリンクが無効になった場合は、楽天市場の別の検索結果のリンクを使ってください)
2)Octoparseでページが読み込みされたら、自動的にページ上の内容を識別します。もし自動識別機能をオフする場合は、右上の操作ヒントパネルで 「Webページを自動識別する」、ページ上の内容を識別します。自動識別とは、自動的にページ上の必要なデータを検出して識別するという役立つ機能です。ポイント&クリックをする必要はなく、Octoparseは自動的に処理します。

3)識別が完了すると、データプレビューで識別したデータを表示され、どのようなデータが取得されているかを確認することができます。「識別結果を切り替える」をクリックすると、ページの異なる場所の識別結果を指定することができます。「ワークフローを生成」をクリックして確認し、タスクを作成します。

ステップ2: タスクを実行する
上の「実行」ボタンをクリックして、すぐタスクを実行できます。たった数分で数千件のデータを取得することができます。これがOctoparseのスピードです。一度Octoparseのコツをつかめば、以前Webデータを取得するための手作業で時間を無駄にしていたことを後悔するに違いありません。

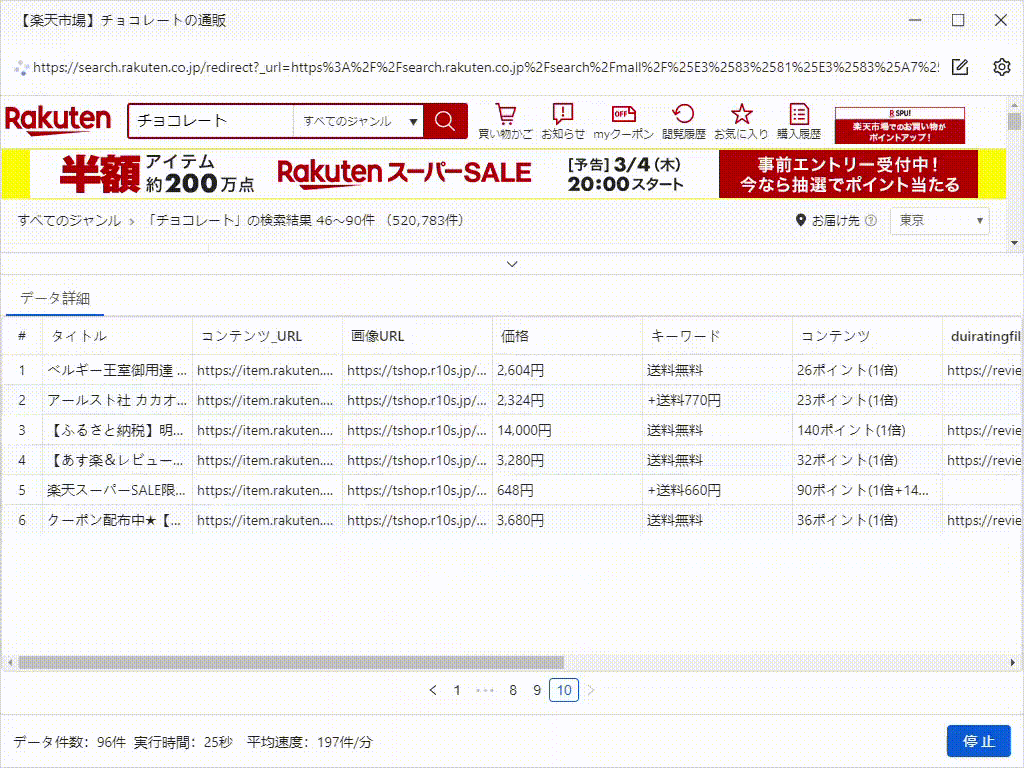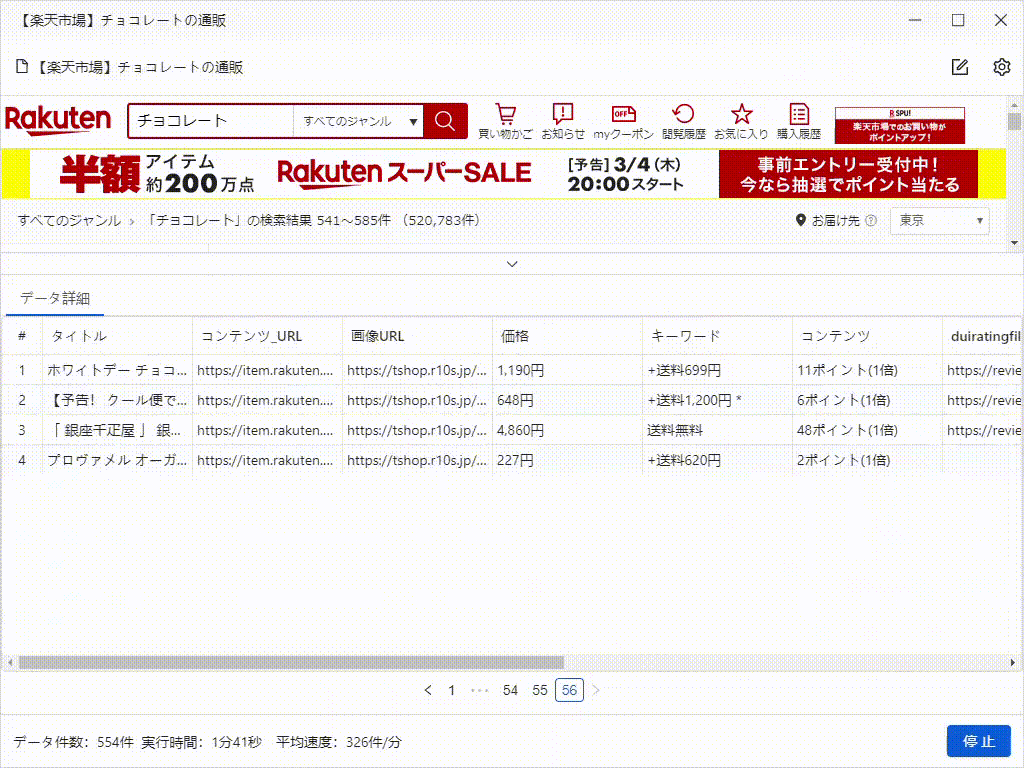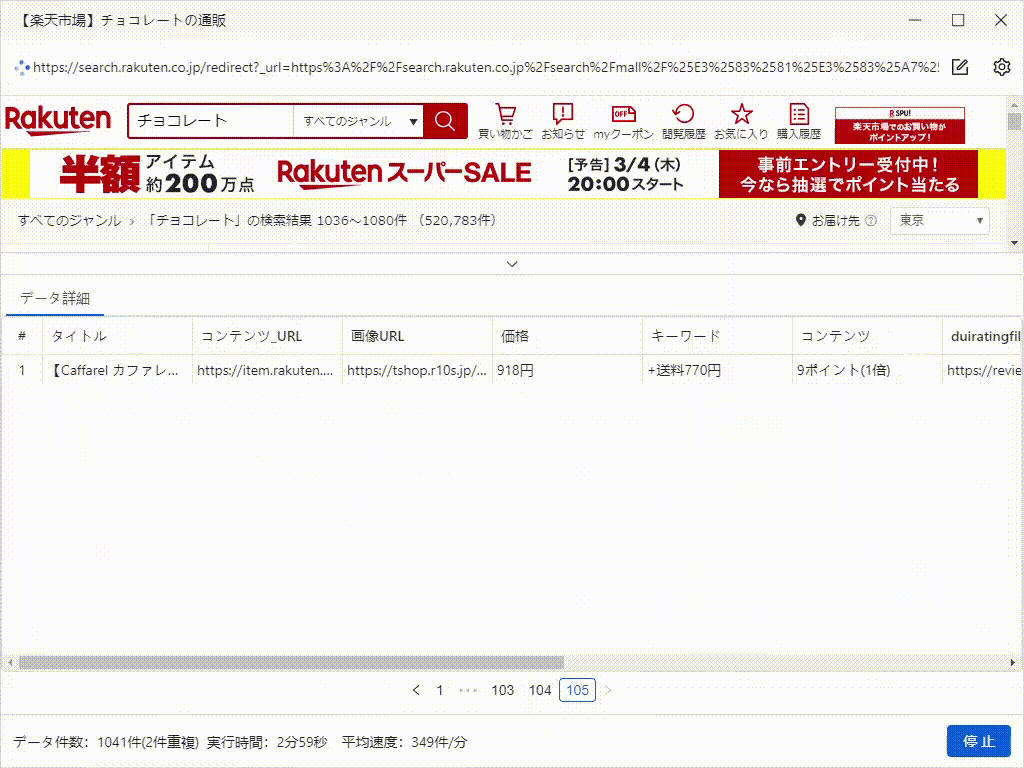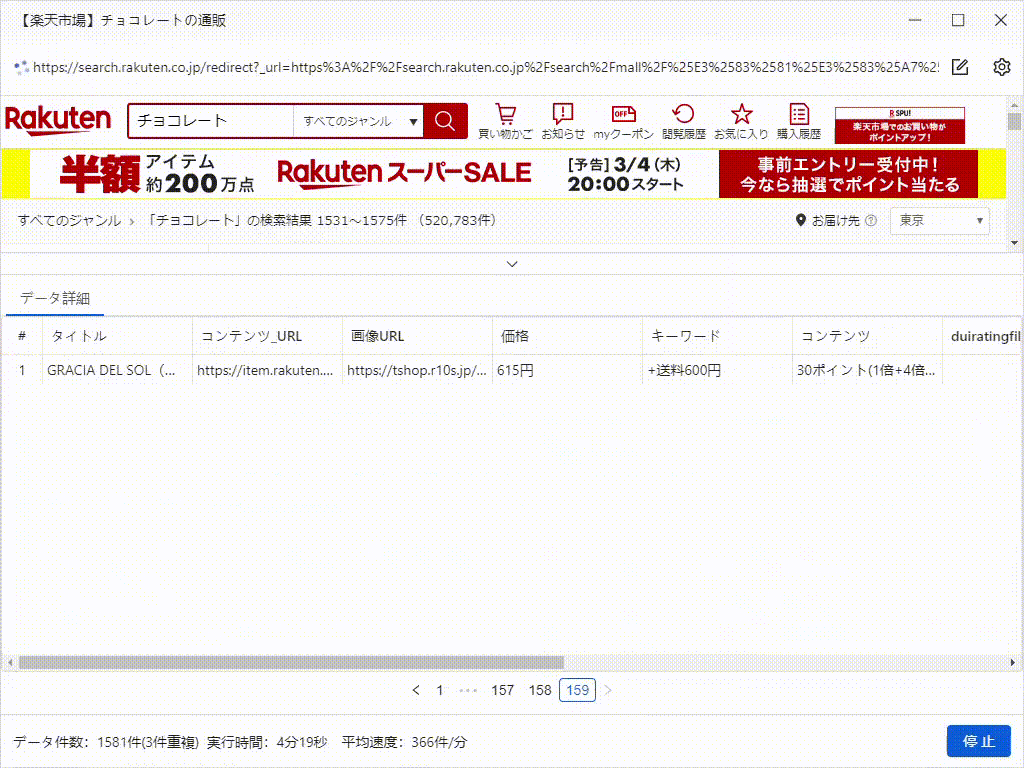
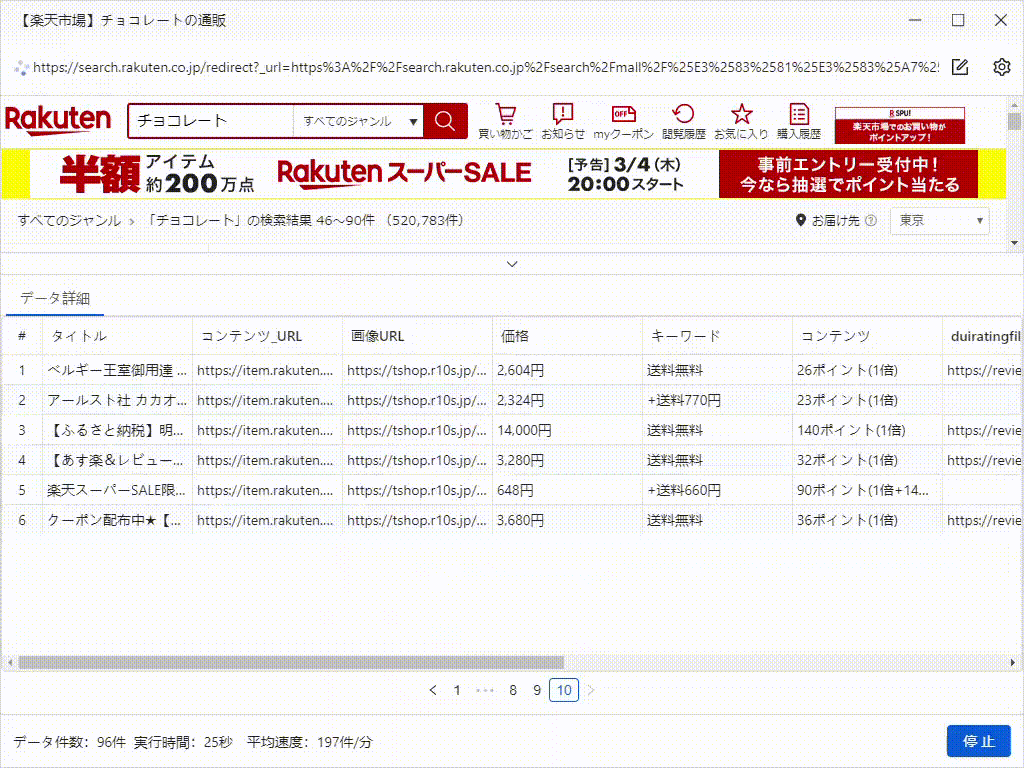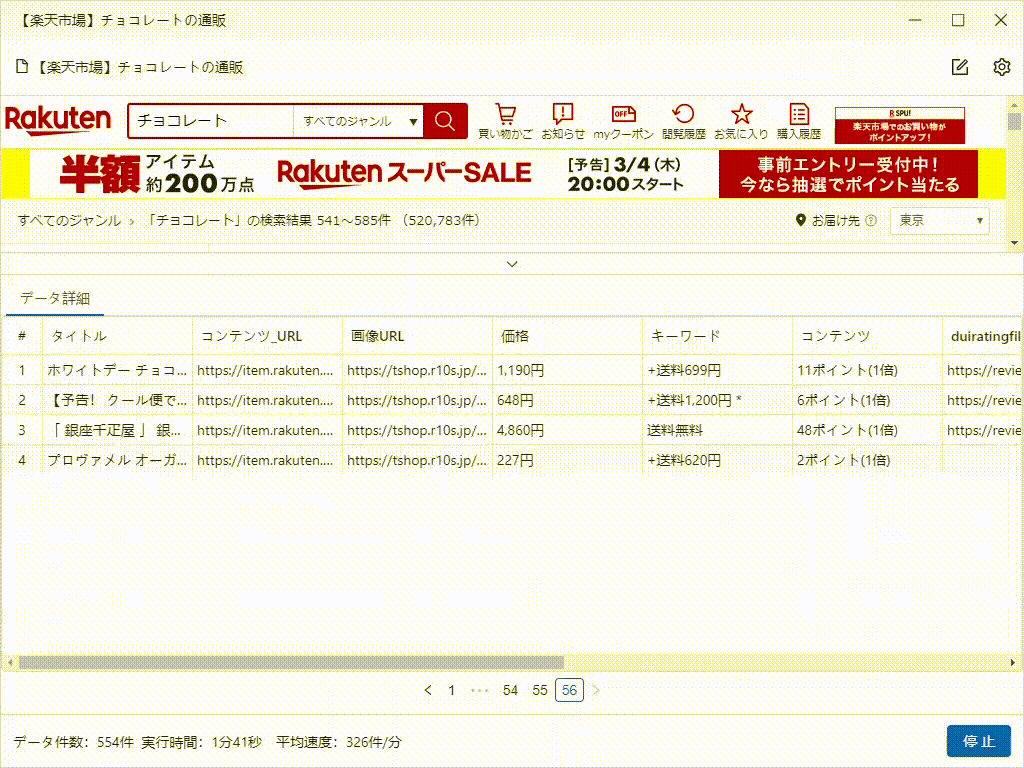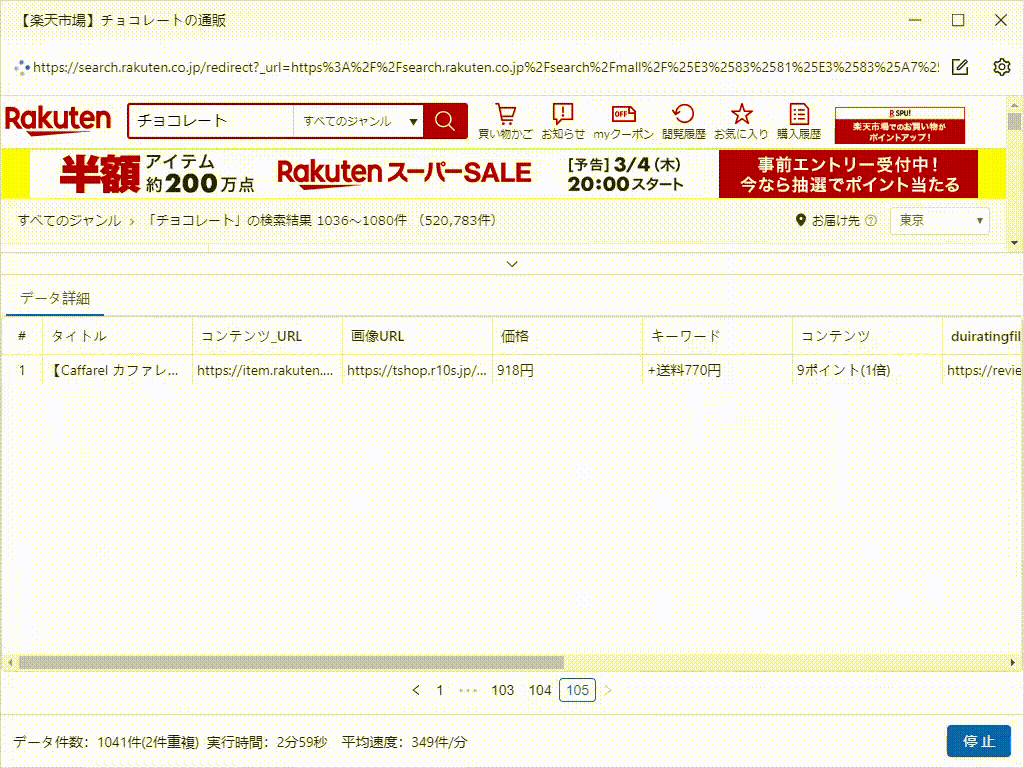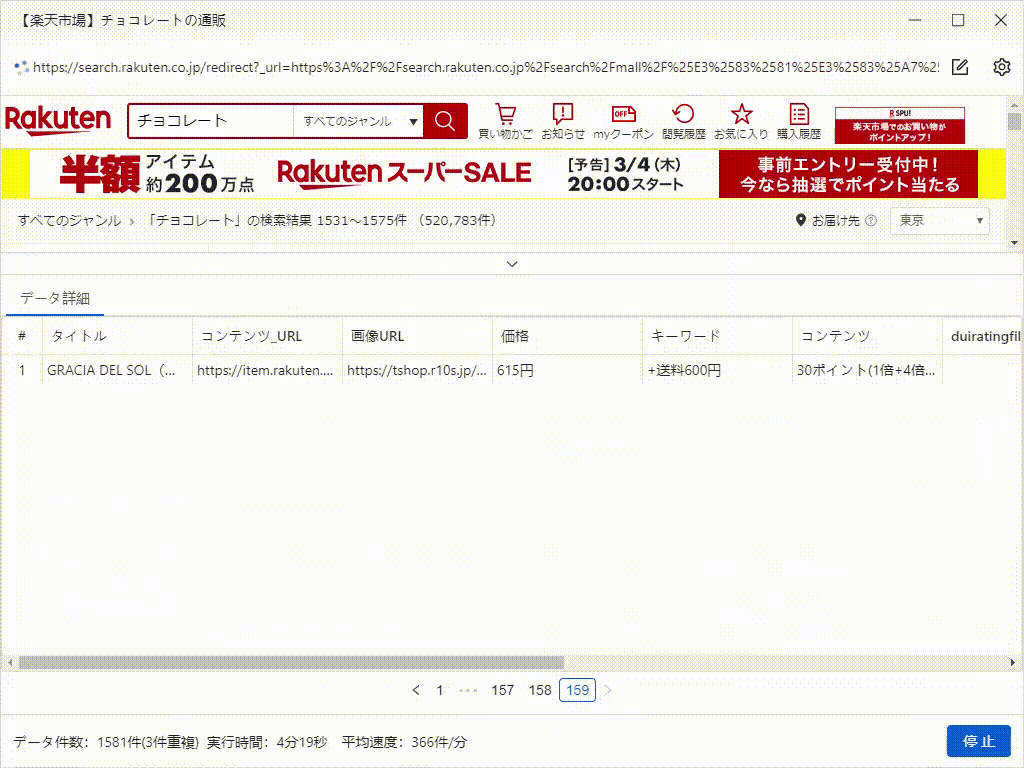
これは、たった5分で抽出したデータです。実際、それはすべての画像のURLだけでなく、製品の詳細ページのデータもスクレイピングできます。これは、競合調査やEC(Eコマース)分析をしている方には、非常に役立つツールです。
4. 数秒で画像を一括ダウンロード!
すべての画像URLをExcelファイルに保存した状態で、この動画から紹介された一括ダウンロードツールを使って、全ての画像をダウンロードします。今回はChromeの「Tab Save」という拡張機能を例として試していきましょう。

画像のURLをコピーしてタブ保存に貼り付け、ダウンロードをクリックすると、すべての画像が数秒でコンピュータにダウンロードされます。

全体のプロセスはわずか10分かかります。楽天市場から画像の数千(サイトに応じて具体的なデータ件数も変わります)をダウンロードできます。ぜひ試してみてください!
もしタスクは不具合な状況がある場合…
今回の例で自動識別による生成したタスクは問題なく実行できますが、もしタスクは不具合な状況がある場合は、どのように修正すればいいでしょうか?
1. ページネーションが無効の場合
このステップでは、ページネーションを確認し、必要に応じてXpathを修正していきます。ページネーションについてこちらでご参照ください。
具体的には、ステップ「ページネーション」をダブルクリックすると、設定画面が表示されます。その設定画面には、自動識別で作成されたXpathがあります。
・どのように修正すればいいでしょうか?
右側の小さな矢印をクリックして、右側の内蔵ブラウザで「次のページ」ボタンをクリックします。これはクローラーに「これが私がクリックしたいボタン」を指示しています。簡単でしょうね。

・もし上記の方法を修正してもダメな場合はどうすればいいでしょうか?
下記の画像の通りに、Xpathを入力してください。
(//a[@class="item -next nextPage"][contains(string(),"次のページ")][not(@disabled)])[1]

2. 画像が読み込まないの場合
ページが完全に読み込みされるため、スクロールダウンの設定が必要となります。このステップは、スクロールダウンを設定することです。Octoparseで数回のクリックするだけで設定できます!
ワークフローに戻って、「Webページを開く」をダブルクリックし、「Webページを読み込んだ後」で「スクロールダウン」にチェックを入れ、2秒間隔でスクロール1回、回数50回を設定します。

これでタスクの修正は完了です!
5. まとめ
- Octoparseは、無料プランも提供しているWebスクレイピングツールです。ノーコード技術を使うため、非エンジニアでもスクレイピングすることができます。Webスクレイピングプロジェクトを1から始める最適なツールです。
- Octoparseの自動識別機能を利用して、Webサイトから簡単にデータを取得することができます。これにより、他のツールでややこしいステップ設定から解放されます。
- 自動識別機能を利用して、Xpathを書く必要はありません!ポイント&クリックだけでテキストやボタンなどの内容を指定できます。これは最もやりやすい方法です。
参考記事:
画像を一括ダウンロードするのに超便利なツール5選
注目のWebスクレイピングツール5選を徹底比較!
ECサイトからデータを抽出する3つの課題
Webスクレイピングによる価格戦略・価格の決め方