【SEO対策】アクセス数を倍増させる!良質な被リンクの増やす方法

元記事:https://www.octoparse.jp/blog/how-to-write-articles-that-can-attract-the-most-backlinks/
リンクビルディングとは、他のWebサイトから自分のサイトに対して被リンクを獲得することです。被リンクはSEO対策では決定的な部分です。しかし、2019年5月16日に「Page Quality Raters Guidelines(Webページ品質評価ガイドライン)」が登場したことで、被リンクの効果的な作ることが難しくなっています。
被リンクとは、「良質な被リンク」(ナチュラルリンク)と「悪質な被リンク」(スパムリンク)があります。良質な被リンクは自然に獲得した被リンクのことです。悪質な被リンクは、SEO効果がないどころかGoogleなどの検索エンジンから罰の対象になるというケースもあります。
それだけでなく、被リンクは、単純に「リンク」ではなく、Webページの品質基準を満たし、ユーザーがWebサイトを閲覧する際の体験を向上させる対応策も実施する必要となります。
ここでは、初心者に向けて良質な被リンクを獲得して、アクセス数とSEO効果を倍増させるいくつかの方法とコツを紹介します。
目次
1. 独自のデータ分析を行うこと
根拠のないデータでは、読者からの信頼を得ることは非常に難しいです。人々は、データに裏付けられた証拠のあるコンテンツに賛成すれば、共有する傾向もあります。例として、この記事は読者に役立つデータや深い分析レポートを提供している記事であれば、人々は記事のリンクをTwitterやFacebookなどのSNSを通じてコンテンツを拡散して、より多くの人に興味をもってもらいやすくなります。
2. 「情報源」になること
自分で調べて、自分のアイデアを裏付けるのに必要なデータを集めてください。その分、作業量が増えることになるかもしれません。しかし、データが明確に示され、議論が人々にインスピレーションを与える限り、長い目で見れば、その価値は多く被リンクを獲得することができます。他の人が興味を持ったり、自分の創造に良いものを書きます。そして、他人のニーズに応えることで、被リンクを獲得しているのです。
「How data analysis helps unveil the truth of coronavirus(コロナウイルスの真実をデータ解析で解明する方法)」という記事が良い例です。この記事は、数ヶ月のうちに数百の被リンクを獲得しました。それ自体が話題を呼ぶ効果があるのはもちろんですが、大切なのは、自分でデータを取集・分析して、その状況をもっと知りたい人たちに向けて発表しました。

誰でも既存のレポートや分析結果に満足することはありません。最新のデータを取集して既存のレポートを更新したり、既存のデータを新しい視点で提示したりします。もしノンコーダーなら、大量のWebデータを一度に入手するために、プログラミング不要(ノーコード)のWebスクレイピングツールを使うことをお勧めします。Webスクレイピングのテクニックを身につけてください。これが研究のデータ分析に対して役に立ちます。

データを取集する時、新たな悩みが出てくるかもしれません。高度なデータ分析に長けた経験豊富な著者として、複雑な研究課題に取り組むことを求められているだけではなく、良い視点を選んで、根拠をもって詳しく説明し、情報源になるために頑張りましょう。
それだけではありません。自分のレポートの情報源になるだけでなく、先行する研究者の分析結果を参考にすることもできます。権威あるサイトに被リンクすることで、自分のサイトの検索順位に良い影響を与えます。要するに、良い文章を書きましょう。
3. 情報を分かりやすく視覚的になること
インフォグラフィック(視覚情報化)であることは、読みやすくなります。読者に記事を読んでもらえないのであれば、どんなに価値のある洞察に満ちたアイデアであっても、執筆から編集までの一連の作業の意味がありません。
データだらけは退屈です。読み方が理解しやすいように、データを視覚化してみましょう。人間は視覚に強く依存する生き物です。視覚的に表現するというグラフィック情報は、テキストよりも人々に伝えやすくなります。
同じグループの人たちに向けて、同じトピックについて書いているコンテンツ著者がたくさんいますので、記事の一部の内容を人に興味を持ってくれたら、より多くの閲覧数を獲得することができます。この記事が他の著者の参考になれば、より多くの被リンクを獲得できます。
したがって、画像グラフにロゴやキーワードを入れるべきなのです。そして、被リンクことはあっても、ロゴが消された状態で、宣伝効果になるかもしれません。
ビジュアルデザイナーの方は、データ視覚化になるため、Visme、或いはAdobeのツールをぜひ試してみてください。
4. 上手な見出しの書くこと
多くの人は見出しを見て、この文章を読むかを決めています。
例として、「コンテンツマーケティング事例から見る!成功の秘訣」という見出しは、人はクリックしてしまう。原因としては、「成功」、「秘訣」という言葉は、人々の想像力を刺激し、すぐにドーパミンが作用し始めます。もしコンテンツマーケティングを始めたばかりであれば、この見出しは訴求ポイントによってユーザーは行動を起こします。
見出しはとてもシンプルで些細なことのように見えますが、多くの人は見落としてしまいます。普段は、ただクリックするだけで、その後にあるメカニズムを考えないような時もあります。見出しの書き方についてはもっと学ぶ必要があると思っています。
新しい記事に対して、魔法のような見出しを作るには、Googleで検索して、上位に表示されている見出しを分析してから書きます。重要度の高いサイトについては、メインコンテンツを書き終えた後、関連するキーワードをリストアップし、上位にランキングされている記事の見出しをWeb上からかき集めて、それを分析します。
良い検索順位を得ると、被リンクを増やすことができ、SEO効果も倍増させます。
5. まとめ
簡単に言えば、方法は以下になります。
・価値あるデータの発信者となる
・価値あるデータの情報源となる
・読者の興味を引くような見出しをつける
もっと良いコンテンツを作れるように、一緒に頑張りましょう。
関連記事
業務自動化の未来へ進発!RPAツール導入方法・おすすめRPAツール8選
1. RPAとは?
RPAは「Robotic Process Automation」の略称です。簡単に言うと、RPAの主な目的は、重複的で文書化されたありふれた作業をすべてロボットに行わせることです。
2. RPAによる影響力
RPAツールを導入実績がある業界は、単に銀行、金融サービス、保険業界だけではありません。業務自動化を推進しているため、製造業、通信業、航空業、石油・ガス業、小売業、分析業などの業界・産業分野に大きな影響を与えます。
多くの業界・産業分野で、スマートなRPA自動化ツールをビジネスプロセスに導入することが進められています。
RPAツールが登場した前、企業の「社内で開発した自動化ツール」は、簡単なバッチ処理やエクセルの自動化、マクロなどで業務プロセスを処理していました。それらは拡張性や信頼性に欠けていましたが、従業員の生産性も向上させた実績があります。
RPAの自動化ロボットを開発する前に、適切なRPAツールを選択することは最も重要なことです。それは、RPA導入の業務効率化・自動化の効果を直接左右するものだからです。
Gartner社の調査により、世界のRPAソフトウェア支出は、2022年に24億ドルに達すると予想されています。RPA市場は、2024年には約87.5億ドルに達すると予想されています。また、2022年末までに、大企業・大手企業の80%がRPAを導入すると言われています。
しかし、企業は自分の業務に一番適切なRPAツールを選ぶことが非常に難しいです。
この記事は、ここまでビジネスにおけるRPAツール選び方から、現在のトップレベルのRPAツールと、それらの主要機能の比較までを紹介します。
3. RPAツールの選び方
RPAの導入を成功させるためには、プロセス・操作自動化や機械学習などのワークフローを通じたビジネスプロセスの改善への取り組みが必要です。また、自社のニーズやリソースに合った適切なRPAソリューションを選択することも重要です。
業務の目的やプロセスの変革を明確に理解した上で、初期の調査に加えて、具体的な要件をリストアップすることができます。これにより、選択肢が大幅に絞られ、ニーズに合ったツールの選択がより易くなります。
一般的な要件には次のようなものがあります。
- コスト(開発・メンテナンスなど)
- 非構造化データの標準化
- カスタマイズRPA開発可能性
- コア機能の実現可能性
- タスクやワークフローを階層化して自動化プロセスになる可能性
また、RPAの将来的な拡張性に注目することも重要なポイントです。可能であれば、自社の現在および将来のニーズに対応できるRPAプラットフォームを選択することで、追加ソリューションの特定、導入、および自社のデジタルインフラとの共存の確保にかかる時間を短縮することができます。さらに、ツールの拡張性も確保できます。
4. RPAツールを導入する前に考えるべきこと
一般的に、RPAは、これまで人間の監視や直接的な関与を必要としていたさまざまな業務を遂行することができます。しかし、現在のRPAツールは、ビジネスに必要な特定の機能を提供するわけではありません。
考えるべき最も重要なことは、ビジネスのニーズに合わせて、あるソリューションがどのような関連性を持っているかということです。例として、機械学習やコグニティブ・オートメーション、インテリジェント・オートメーションが中心的なニーズであれば、候補となるプロバイダーがその種のツールやソフトウェアを提供できるかどうかを確認べきです。
また、サポートやカスタマーサポートサービスも大事です。
自動化ソフトウェアは、データのプライバシー、管理、統合などの問題を考えなければなりません。
- 自動化のパイロットやテストを担当する管理者は一人でしょうか?
- 現在の業務に不可欠で、まだ見直しや変革を行うべきではない特定の反復作業はありますか?
積極的にサポートしてくれる協力会社がいれば、導入プロセスを円滑に進めることができ、RPAを導入成功するための良い条件を整えます。
5. 2021年おすすめRPAツール8選
5.1. Automation Anywhere
RPAツールで最もよく知られているAutomation Anywhereは、クラウドサービスでWebベースのRPAソリューションで、主にスクリプトを活用して自社の技術スタックに基づいてRPAを構築します。
非常に複雑なRPAプロセスを作成することができます。単純なコピペの定常処理からデータ修正まで、Automation Anywhereは幅広い自動化ニーズに対応する必要な拡張性を提供します。
Automation Anywhereは、数週間で70%のエンドツーエンドの自動化をしていますが、これも、バーチャルワーカーやボットスクリプトを設定する必要な時間です。また、顧客体験を50%向上させるという実績もあります。

ー料金表ー
※30日無料トライアルあり
Cloud Starter Pack: $750/月
Advanced Pack: 要問い合わせ
5.2. Blue Prism
RPA業界で最も歴史長いツールであるBlue Prismは、近年着実に成長しています。
Blue Prismは、フォーチュン企業のエンドツーエンドのRPAに特化しています。また、Blue Prismは、トップクラスの無人ロボットを提供しています。ロボットは非常に洗練されているだけでなく、高度なRPAネットワークを設定するための深いスクリプト機能も備えています。
Blue Prismを組織全体で使用するためには、堅牢な開発フレームワークへのコストが必要です。一方、Blue Prismは優れたデバッグ機能と圧倒的な拡張性も備えています。

ー料金表ー
※無料トライアルあり
要問い合わせ
5.3. UiPath
UiPathには優れたのは、「使いやすさ」という点です。
UiPathは、インストールが簡単で、UIベースの開発機能を備えています。最も重要なのは、強力なオンラインチュートリアルセクションが、ソフトウェアに慣れるのに役立つということです。ガートナーのクアドラントレビューによると、UiPathは一流のカスタマーサポートチームを持ち、すべてを考慮すると、UiPathは迅速なRPA導入を求める企業にとって理想的です。

ー料金表ー
※無料トライアルあり
Community: 無料
Studio: $2000 ~ $3,000/年
Orchestrator: $20,000/年
Attended Robot: $1,200 ~ $1,800/個
Unattended Robot: $8,000/個
5.4. Octoparse
Octoparseはノーコード(プログラミング不要)で、クリックするだけでWebデータ抽出を自動化するRPAツールです。Webスクレイピングツールとも呼ばれます。従来、手作業(コピペ)で、或いはプログラミングでWebクローラーを構築して、Webページからデータを収集しますが、ものすごく時間がかかります。
データ抽出をよりやすくするために、OctoparseはAmazon・楽天市場・Twitterなどのサイトからすぐにデータを収集するWebスクレイピングテンプレートを提供しています。

パラメータ(ターゲットWebサイトのURL、検索キーワードなど)を入力するだけで、価格情報・商品詳細・Web上の口コミなどのデータが抽出されてきます。クラウド型プラットフォームも提供するので、スケジュール設定も可能です。
他のWebサイトに対して、Octoparseは自動識別機能も提供しています。

リアルタイムデータを自動抽出し、Web上の最新情報をいつでも入手できます。取得したデータはExcel、HTML、CSVなどのフォーマットで、またはデータベースに保存されます。Web上の様々なデータを収集したい場合は、ぜひWebスクレイピングツールを試してみてください。
ー料金表ー
フリープラン:無料(クラウド抽出以外、スクレイピングツールのコア機能を使用可能)
スタンダードプラン:$75/月(年払い)または$89/月(月払い)
※14日間の無料トライアルあり
プロフェッショナルプラン:$209/月(年払い)または$249/月(月払い)
※14日間の無料トライアルあり
5.5. Microsoft Power Automate
Microsoft Power Automateはシンプルでありながら効果的なRPAソリューションを提供します。Microsoft Power Automateの最大のメリットは簡単でセットアップできることです。つまり、マイクロソフトのエコシステムのデータをすぐに利用することができ、RPAを簡単に行うことができます。ロボットワークフォースをオーケストレーション(設定、管理、調整の自動化)するのは役立ちます。

ー料金表ー
Per-user plan: $15/月/1ユーザー
Per-user plan with attended RPA: $40/月/1ユーザー
Per-flow plan: $500~/月/1ユーザー
5.6. Celonis
Celonisは、自動化すべきプロセスを特定する(プロセスマイニング)ことは上手です。そのためには、クラウドの構造や従業員の日常業務を調査します。これにより、システムの状況を把握することができ、チャンスのある分野やプロセスの問題点を明らかにすることができます。
したがって、CelonisはUiPathなどのRPAソリューションとの組み合わせが理想的です。

ー料金表ー
※無料トライアルあり
要問い合わせ
5.7. WinActor
WinActorはNTTグループに開発された純国産RPAツールです。日本国内でサービスインフラ・ソフトウェア通信・金融などの業界でよく導入され、シェアNo.1となっています。業務の手順を「シナリオ」として記憶し、同じ操作を何回でも繰り返し実行することができます。1台のPCでスモールスタートから大規模導入まで幅広く対応可能です。パッケージソフト(Office製品など)からスクラッチ開発の独自システムまで、プログラミングスキルがなくても簡単に操作できます。60日間の無料トライアルも提供し、カスタマーサポートも充実しているので、初めての企業にも安心です。

ー料金表ー
フル機能版:908,000円/年/PC1台
実行版:248,000円/年/PC1台
5.8. SynchRoid
SynchRoidはソフトバンクが開発したRPAツールです。その特徴は「ITスキルが低い社員でも開発できるシンプルなRPA」です。従来、RPAとは開発画面が難しく専門的なスキルが要求されることの多い製品でした。SynchRoidでは、開発画面をGUI(グラフィカル・ユーザー・インターフェース)で提供し、ITや情報システム従事者でなくとも開発者として自動化ロボットを作り出せます。実行環境は、デスクトップおよびサーバーどちらも選択可能です。RPAの導入支援やトレーニングなどのサポートは充実し、多くのシステムとの連携が可能です。

ー料金表ー
ライトパック:900,000円/年
ベーシックパック:600,000/月
6. まとめ
RPAを導入することで、業務効率化を実現することが可能です。データ入力・収集など重複作業をRPAがおこなうことで、重要な仕事に集中できます。RPAツールは安くないが、人件費コストの削減や業務自動化・業務効率化を考えれば、導入の価値はあります。この記事で紹介されたツールは無料トライアルも提供しているので、ツール選びに迷ったら、ぜひ今回紹介したツールを使ってみてください。
関連記事
【YouTube動画】2021年注目の業務自動化ツール30選
【2021年】無料のノーコード(NoCode)開発ツール厳選8選

元記事:
https://www.octoparse.jp/blog/8-best-nocode-development-platforms-and-tools-list/
こんなお悩みはありませんか?
- 「スタートアップを始めたいと思いますが、プログラミングを学んでいる時間がない…」
- 「新サービスを思いついたので、自動化させていきたいが、会社のエンジニアは時間がない…」
- 「Web上の情報を収集する時、手作業すると効率が悪いから、専用のツールが欲しい…」
昔は、複雑なアプリケーションを構築するために、莫大なコスト、複数の開発者、膨大な開発時間を必要です。正直と言うと、プログラミングを学ぶのは大変です。
現在、プログラミングを学ばなくても、素晴らしいWebホームページ、アプリケーションや自動化ツールなどを開発することができます。
したがって、ノーコード(NoCode)はインターネットの未来です。
去年から、ノーコードツールを開発したスタートアップが急成長しています。巨大テック(Google・Amazon・Microsoftなど)企業も続々ノーコードに参入しました。
業務自動化をワークフローで簡単に構築したり、ビジネスプロセスを改善したり、オペレーションや成長を支援するために必要なあらゆることもできます。
昔は多くのWebページやアプリケーションのデザインと開発は、コードを動作させるために昼夜を問わず働かなければならない開発者に依存していました。
2021年に、コーディングなしで、誰でも様々な機能を開発することができるという「ノーコードツール」がいっぱい登場されています。
業務自動化、Webサイトの作成やアプリの開発など、難しいことでもノーコードツールがあれば、簡単に実現できます。
そもそも、ノーコードとは何でしょうか?
目次
3. Webサイトを構築できるノーコード(NoCode)ツール
4. Webアプリを開発できるノーコード(NoCode)ツール
5. 業務自動化・効率化できるノーコード(NoCode)ツール
1. ノーコードとは?
簡単に言うと、ノーコードとは、プログラミングを勉強をせずに、コードを書かずにGUI(グラフィカル・ユーザ・インターフェース、Graphic User Interface)を使って、アプリを開発、自動化プロセスに動かせることです。
しかし、「ノーコード」というのは、本当に「コードがない」ということではありません。実際には、ツールを開発した人たちがコーディングで開発されて、GUI経由でユーザーは簡単に開発できるようなツールです。ツールを使用するユーザー・企業にとって、より簡単な体験を提供しています。開発する必要な操作は、クリック、スクロール、またはドラッグ&ドロップだけです。
「開発」は大衆にとってより身近なものとなり、テクノロジーの新しい時代が来ています。
2. ノーコードツールで何ができる?
ノーコードツールで作れるものは限られていません。Webサイトの構築からアプリの製作まで、可能性は無限大です。仕事を自動化したり、Web上の情報を自動取集したり、データを整理したり、ノーコードツールで解決可能です。
オンラインでアンケートを作成したことがありますよね?あれもノーコードです。
ノーコードといっても、特定の分野に特化したものではなく、さまざまな種類のツールがあります。以下のリストでは、おすすめのノーコードツールを紹介します。
3. Webサイトを構築できるノーコード(NoCode)ツール
3.1. Webflow
Webflowは、「レスポンシブWebサイトをデザインして立ち上げることができる」というWebサイト構築プラットフォームです。他のWebサイトビルダーを使った経験があるかもしれませんが、Webflowはとても使いやすいに感じられます。
多くのWebサイトビルダーでは、ある程度のカスタマイズが可能ですが、Webflowでは、クリックしてスクロールするだけでWebサイトを構築することができます。
さらに、カスタマイズ性にも優れています。ゼロからスタートして、自分の好きなようにフルレスポンシブ(スマホ、タブレット、PCのどの端末でも最適な画面表示)なWebサイトを構築することもできるし、手っ取り早く済ませたいならテンプレートを使うこともできます。
ー料金表ー
※個人向けプランの場合、無料で始められます。
会社向けプランの場合:
Lite:$16/月
Pro:$35/月
3.2. Carrd
Webflowより早く、より簡単な方法でWebサイト構築ツールです。
Carrdは、よりシンプルなWebサイトを構築するための完璧なノーコードツールです。Carrdは他のツールと同じようにパワフルですが、方向が違いますのでご注意ください。
Carrdは、テンプレートを使って、あるいはゼロからカスタマイズできる1ページのWebサイトを構築するために設計されています。そのシンプルさと安い価格なので、筆者はおすすめリストに入れました。

ー料金表ー
※無料プランで始められます。(3つのWebサイトまで)
Pro:$19/年
4. Webアプリを開発できるノーコード(NoCode)ツール
4.1. Bubble
Webアプリケーションを構築する必要があるなら、Bubbleは最適です。
Bubbleは、アプリ全体をプロトタイプ化し、数時間で構築して立ち上げて、効率的にビジネス成長を拡大する機会を与えてくれます。内部ツールも備え、機能性と使いやすさを同時に実現しています。
しかし、筆者がこの製品に惚れ込んだのは、クリックによる操作やUIコンポーネントの配置だけでWebアプリが作れます。Webアプリはこんなに簡単になるのは思えませんでした。

ー料金表ー
Hobby:無料
Personal:$25/月(年払い)または$29/月(月払い)
Professional:$115/月(年払い)または$129/月(月払い)
Production:$475/月(年払い)または$529/月(月払い)
4.2. Glide
Glideは「高速でアプリが作れる」という点が一番特徴的です。
Glideとは、Googleのスプレッドシートを「データベース」として利用し、Webアプリが作れるノーコードツールです。アプリのデザインも最初からテンプレートが用意されていて、テンプレートを使ってもいいし、要望に応じてデザインをカスタマイズすることもできます。

ー料金表ー
Pro App:$19/月(年払い)または$29/月(月払い)
Business App:$99/月
5. 業務自動化・効率化できるノーコード(NoCode)ツール
5.1. Octoparse
簡単と言えば、Octoparseは直感的に操作ができるWebスクレイピングツールです。
Webスクレイピングとは、「Webサイトからデータを集めて抽出する技術」で、「Webクローリング」と「Webスパイダー」も同じ意味です。
Web上の情報を手作業でまとめるのは非常に時間がかかります。Webサイトのクチコミやレビューなどの情報を自動で収集する時、通常はPythonなどのプログラミング言語で開発する必要があります。
Webスクレイピングツールは、プログラミング言語の知識がない人でも手軽にWebからデータを収集して抽出することができるよう設計されたツールです。

それだけでなく、Octoparseは以下の様々な機能があります。
・自動識別機能搭載
Octoparseには自動識別機能が搭載されています。クリックするだけでワークフローを自動的に生成して、スクレイピングが開始できます。

・様々なサイトに対応可能
Octoparseは静的なWebサイトやAJAXやJavaScript技術を使っている動的Webサイトに対応しています。
・便利なテンプレートを提供する
テンプレートで、URLかキーワードパラメーターを入力するだけで、データを取得できます。現在、70個を超える人気のあるWebサイトのテンプレートがあります。 タスクを作る手間がかからなくても、すぐに欲しいデータを手に入れることができます。
・スケジュールで実行可能
スケジュールを設定しておけば、自動的にデータを取得することが可能です。
複数サイトを自動的にデータを抽出したい場合に、Octoparseは強力な味方となります。Web上の情報を収集したい方はぜひ試してみてください。
ー料金表ー
フリープラン:無料(クラウド抽出以外、スクレイピングツールのコア機能を使用可能)
スタンダードプラン:$75/月(年払い)または$89/月(月払い)
※14日間の無料トライアルあり
プロフェッショナルプラン:$209/月(年払い)または$249/月(月払い)
※14日間の無料トライアルあり
5.2. UserGuiding
BubbleでWebサイトやWebアプリを開発した後は、チュートリアルはすごく大事です。
UserGuidingはユーザーガイドとユーザーオンボーディング(新規ユーザーの最初のログインから始まり、ユーザーがハッと気づくまでの重要なプロセスのこと)製品に最適なユーザーオンボーディング体験を作るツールです。
UserGuidingは、ブラウザの拡張機能として動作し、お客様の製品上で直接動作します。
さらに、ユーザーをセグメント化してパーソナライズされた体験を作り、目的に応じて必要なオンボーディング要素だけを通過させることができます。
また、UserGuidingでは、作成したコンテンツのパフォーマンスを詳細な分析ツールで追跡することができます。

ー料金表ー
Start-up:$199/月
Growth:$399/月
5.3. Zapier
Zapierは業務を自動化することができるiPaaSです。OctoparseサポートチームもZapierを利用しています。
Zapierは、1500種類以上のWebアプリやツールを組み合わせて連携することで、自動化のシステムを構築します。
自動化のシステムは、従来ならエンジニアに依頼して個別のプログラム開発が必要でした。
Zapierでブラウザ上の操作だけで、誰でも簡単に使える非常に便利なツールです。

ー料金表ー
※無料プランで始められます。(100タスクまで)
Starter:$19.99/月 (750タスク)
Professional:$49/月(2000タスク)
Team:$299/月(50000タスク)
Company:$599/月(100000タスク)
5.4. Voiceflow
2011年にSiriが音声アシスタントとしてデビューして以来、ボイスアシスタントは長い道のりを歩んできました。AmazonのAlexaやGoogleアシスタントがSiriのすぐ隣に位置するようになり、音声技術がノーコードのツールになる時期がやってきました。
自分の音声アシスタントをもっとカスタマイズできたらいいと思いませんか?
Voiceflowはまさにそれを実現します。
Voiceflowでは、ブラウザ上でプロトタイプを作成したり、ワンクリックでアップロードできる機能を使って実際の音声デバイスで試すことができます。VoiceflowはAlexaやGoogle Assistantにも使えますし、チームで作業している場合は、そのためだけのスペースがツール内に用意されています。
Voiceflowが特に優れているのは、おそらくUI(ユーザーインターフェース)です。このツールでは、ドラッグ&ドロップ方式により、音声アプリを効率的かつ楽しく視覚的に開発することができます。

ー料金表ー
Starter:無料
Pro:$40/月
Team:$140/月
6. まとめ
ノーコードは、ビジネス、テクノロジー、そして開発を確実に変えていきます。この記事で紹介できなかったツールもたくさんありますが、ツール選びに迷ったら、ぜひ今回紹介したツールを使ってみてください。
ノーコードツールが深く浸透するようになれば、開発をスピードアップすることができ、アイデアがより具現化しやすくなり、ビジネスのスピードも一層加速していくでしょう。
時代に乗り遅れることのないよう、今のうちにノーコードツールを使ってみませんか。

【初心者向け】ExcelとVBAでWebスクレイピング実戦!

元記事:https://www.octoparse.jp/blog/intro-to-web-scraping-with-excel-vba/
スクレイピングとは、WebページのHTMLコードから、必要な情報やデータを抽出することです。言い換えれば、自動的にWebページ上のデータを収集する技術です。
現在、スクレイピングの一般的なプログラミング言語は、Python、Ruby、JAVA、PHPなどができますが、開発環境構築と環境設定は初心者に対しては非常に難しいです。
したがって、この記事で紹介するVBAは以下のメリットがあります。
それでは、ExcelとVBAを使って、Webサイトから情報やデータをExcelシートに取り込むというExcelマクロを実際に作成してみましょう。
一、Excelでスクレイピングライブラリを導入
ExcelでのWebスクレイピングを配置する前に、Excelのマクロに対してライブラリを導入しなければなりません。
手順は以下になります。
1. Excelを開いて、「空白のブック」を選択します。

2. リボン欄の「開発」をクリックします。

3. 左側の「Visual Basic」ボタンを選択します。

4. 「挿入」をクリックして、「標準モジュール」を選択します。

5. 下記のコードを入力してください。
Sub test()
End sub
結果は以下になっております。

6.「ツール」をクリックして、「参照設定」をクリックします。
「Microsoft HTML Object Library」と「Microsoft Internet Controls」のチェックを入れます。


モジュールとは、プログラムにおいて特定の機能を持ったひとまとまりの構成要素です。選択されたのモジュールは、ブラウザ連動とHTMLコードを読み込むという機能が持っています。
それで、Webクローラーの開発が必要なものは設定完了です。
二、Webサイトにアクセスする
早速ですが、ExcelのVBAを使って、IEブラウザ経由でWebサイトにアクセスします。
これには、ナビゲート属性を使用します。この属性では、URLを二重引用符で囲んで渡す必要があります。詳しくは下記のコードに参照してください。
Sub test()
Dim ie As New InternetExplorer
Dim doc As New HTMLDocument
Dim ecoll As Object
ie.Visible = True
ie.navigate"http://test-sites.octoparse.com/?page_id=192"
Do
DoEvents
Loop Until ie.readyState = READYSTATE_COMPLETE
End sub
F5を押して、マクロを実行します。そこで次のようなWebページが表示されます。

三、VBAでスクレイピングしましょう
今回はボタンを押すたびに、Webサイト上データが自動的にエクセルに取り込まれるように開発しましょう。
まず、Webサイトから、要素(HTMLドキュメント)を検証し、データがどのように構成されているかを分析する必要があります。HTML基礎知識はこちらのリンクで参照ください。今回はテーブルのデータを抽出するように試してみましょう。
1. Ctrl + Shift + I を押して、テーブルの要素を指定すると、HTMLのソースコードに表示されます。
したがって、テーブルの要素は「table」と分かっています。

2. VBAで要素「table」を抽出します。ソースコードでは以下のようになります。
Sub test()
Dim ie As New InternetExplorer
Dim doc As New HTMLDocument
Dim ecoll As Object
ie.Visible = True
ie.navigate "http://test-sites.octoparse.com/?page_id=192"
Do
DoEvents
Loop Until ie.readyState = READYSTATE_COMPLETE
Set doc = ie.document
Set ecoll = doc.getElementsByTagName("table")
End Sub
Excelは、Excelシートの範囲属性を使って、またはExcelシートのセル属性を使って初期化することができます。VBAスクリプトの複雑さを軽減するために、収集データはワークブックに存在するシート1のExcelセル属性に初期化される。
3. 実行ボタンを指定します。
マクロスクリプトの準備ができたら、サブルーチンをExcelボタンに渡して割り当て、VBAのモジュールを終了する。ボタンに適当な名前をつけておきます。この例では、ボタンは「データ抽出」として初期化されます。
手順は以下になります。


4. ボタンを押して、以下のような情報が出力します。

四、Octoparseでスクレイピングする方法
プログラミングが苦手、或いは英語のコードばかりなので苦手意識を持っている方は、スクレイピングツールのOctoparseはおすすめします。
Octoparseは「自動識別」機能があるので、ページのURLを入力するだけで、Webページ上各項目のデータ(テキストとリンクを含む)、「次のページ」ボタン、「もっと見る」ボタン、およびページのスクロールダウンを自動的に検出し、タスク(Webクローラー)を自動的に生成することができます。
早速ですが、Octoparseで自動化の魅力を体験してみましょう。
1. Octoparseを起動して、スクレイピングしたいWebページのURLを入力します。
「抽出開始」 ボタンをクリックして進みます。

2. Octoparseでページが読み込みされたら、自動的にページ上の内容を識別します。
自動識別とは、自動的にページ上の必要なデータを検出して識別するという役立つ機能です。ポイント&クリックをする必要はなく、Octoparseは自動的に処理します。

3. 識別が完了すると、データプレビューで識別したデータを表示され、確認してから「ワークフローの生成」ボタンを押します。

4. これで簡単にWebクローラーが作成しました!
上の「実行」ボタンをクリックして、すぐデータを抽出できます。簡単ではないでしょうか。

五、まとめ
VBAでスクレイピングは簡単にはできますが、複雑な構造を持つWebサイト(JavaScript、AJAX技術を使っている動的サイトなど)では、VBAの機能はちょっと足りないかもしれません。
それだけでなく、スクレイピングしようと思ったら、プログラミング言語とIT知識を勉強する必要があります。完璧に学ぶ時間がなく、効率的にスクレイピングがしたい、プログラミングが苦手、或いは英語のコードばかりなので苦手意識を持っている方はスクレイピングツールはおすすめです。
関連記事
Python vs Octoparse!初心者向きのスクレイピング方法はどっち?
【完全初心者向け】求人情報を一括で自動的に取得する方法公開!
Webページ上の画像を一括保存(ダウンロード)する方法4選

元記事:https://www.octoparse.jp/blog/4-ways-to-scrape-images-from-web-pages-or-websites/
InstagramやPinterestなどの写真プラットフォームには非常に多くの素晴らしい写真があり、デザインの制作や商品の資料作成など画像素材を利用するシーンが様々です。
保存したい画像が少ない場合は「右クリック → 名前を付けてファイルを保存」でも問題ないですが、複数あった場合は時間も手間もかかってしまうと思います。
この記事では、Webサイトから画像を効率的に一括保存(ダウンロード)する4つの方法を紹介します。 数回のクリックで欲しい画像を簡単に手に入れることができますので、早速試してみましょう!
ブラウザツールで画像を一括保存する方法
単一のWebページから画像をダウンロード場合は、ブラウザツールで十分です。
もし複数のWebページから画像をダウンロードしたいならば、Webスクレイピングツールはおすすめです。
1. Firefoxを利用する場合
以下の手順でサイトの画像を全てダウンロードすることができます。

Firefoxで画像を取得したいWebサイトを開きます。空白部分を右クリックすると、「ページの情報を表示」のオプションをクリックします。そうすると、ページ情報が表示されます。

上の「メディア」アイコンをクリックします。ダウンロードする画像のURLのリストが表示されます。「すべて選択 → 名前を付けて保存」をクリックします。指定したフォルダーに画像が保存されていれば完了です。

2. Chromeを利用する場合
この記事から紹介された一括ダウンロードツールを使って、全ての画像をダウンロードします。
今回はChromeの「Image downloader」という拡張機能を試してみましょう。
Chromeで画像を取得したいWebサイトを開きます。「Image downloader」というChromeの拡張機能を起動すると、このツールは自動的に小さな画像(例:サイトのアイコン、ロゴなど)を取り除き、通常サイズの写真だけを指定するという役立つフィルターを提供しています。

3. Webサイトの画像を一括でダウンロードするツール
以上紹介した方法では、単一のWebページであれば使いやすいです。画像以外のデータ、Webスクレイピングツールは画像に関連するそれぞれのデータ(例として、商品名、商品価格、画像のURLなど)を抽出する最適化ツールです。「IMAGE CYBORG」はおすすめです。
Webスクレイピングツールで画像を一括保存する方法
4. Webスクレイピングツールを挑戦してみましょう!
上記の単一のWebページの画像ダウンロードツールとは異なり、Webスクレイピングツール(ここではOctoparseを例として)は必要な画像のURLを取得することが役立ちます。そして、すべてのURLを取得したら、画像を一括ダウンロードすることができます。
Octoparseの利用シーンは?
- 「複数Webページから画像をダウンロードしてほしい」
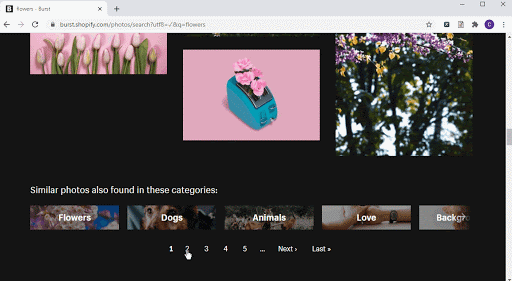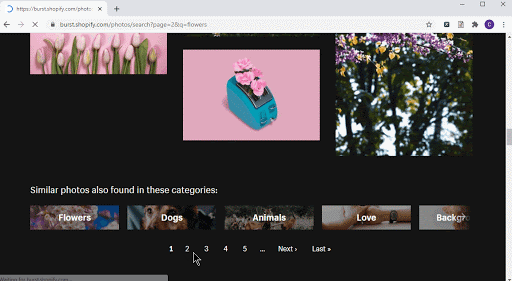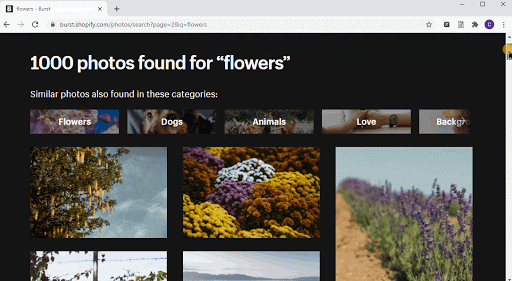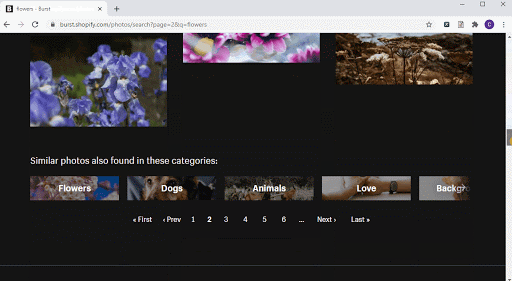
ページネーションを設定した上で、Octoparseは自動的に複数のページから画像のURLをスクレイピングします。作業自動化を通じて、Octoparseは操作の時間を節約できます。
- 「無限にスクロールするWebサイトから画像をダウンロードしてほしい」
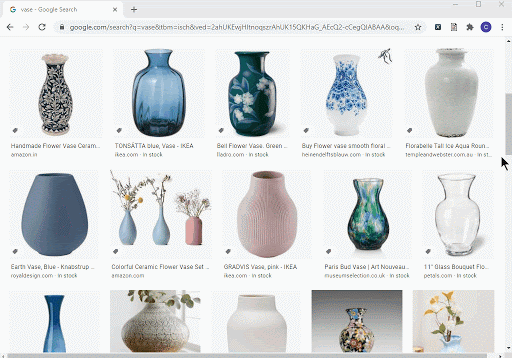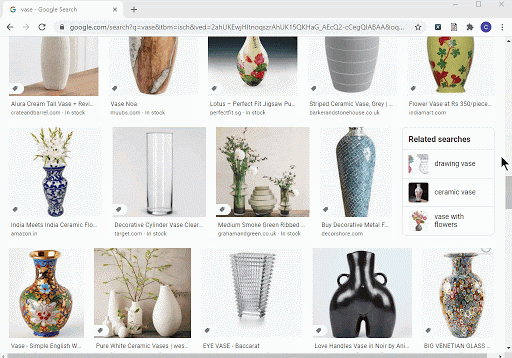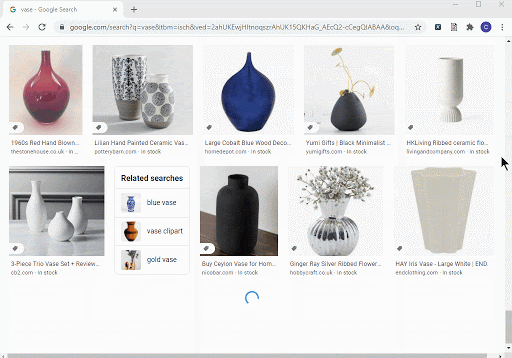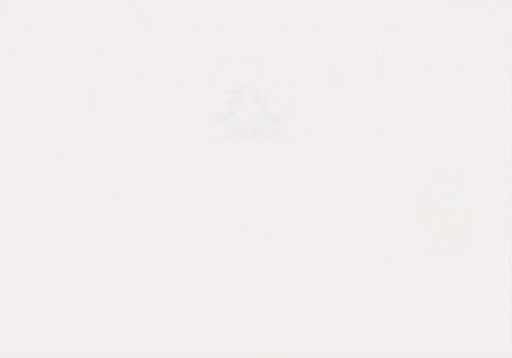
Google 画像検索は無限スクロールを使用しています
例として、無限スクロールを使用しており、新しいコンテンツの読み込みを有効にするために、下にスクロールする必要があります。Webスクレイピングツールは、すべての画像を読み込まれて取得できます。
この記事で紹介したOctoparseには、人間の操作をシミュレート技術が使用されています。したがって、下までスクロールするように設定することができます。
- 「画像だけでなく、それに関連する他の情報もほしい」
例として、Eコマース業者は、ECサイトから抽出したいデータは商品画像だけではなく、価格やメーカー情報などの情報もほしいです。抽出したデータは見込み顧客育成、リスク管理、学術研究、市場分析にも使用できます。

Octoparseでは、Amazonや楽天市場、食べログ、Bookingなどのサイトから簡単にスクレイピングするというタスクテンプレートを提供しています。画像のURLだけでなく、商品やレストラン、ホテルなどの他の情報もスクレイピングすることができます。

Octoparseの人気テンプレート
これで、2つのデータセット(画像と関連する詳細情報)が手に入れたので、自作の商品データベースで市場調査を始めましょう。
初心者向けのチュートリアル
この記事は、Octoparseで楽天市場から画像を一括保存するのチュートリアルです。自動識別機能を通じて、ノーコード(プログラミング不要)で、数回のクリックだけで簡単にスクレイピングできます。さらに、6分間で2000枚以上の画像URLを抽出することが可能です。一度Octoparseのコツを掴めば、他のWebサイトでも簡単に抽出できます。
関連記事
Webサイトから画像を一括ダウンロードする方法

元記事:https://www.octoparse.jp/blog/how-to-scrape-and-bulk-download-images-from-any-website/
1. Webサイトから画像を取得する方法
Webサイトから全ての画像を一括で保存したいとき、1枚ずつ保存するのは非常に面倒です。これは非常に退屈なプロセスであり、仕事の効率を低下させます。
実際、Webスクレイピングツールは、この作業を自動化するの最適な選択肢です。Webページを無限にクリックする代わりに、5分以内にタスクを設定するだけで、クローラーがすべての画像URLを取得してくれます。画像を一括でダウンロードツールにコピーすると、わずか10分で完成させます。
2. Webスクレイピングツールをダウンロード
まずは「Webスクレイピングツールにオススメの10選」という記事から自分に合ったWebスクレイピングツールを探しましょう!今回は、上記の記事から紹介されたOctoparseを例として紹介します。
なお、これは簡単なガイドであり、プログラミングの経験は必要ありません。心配しないでください。
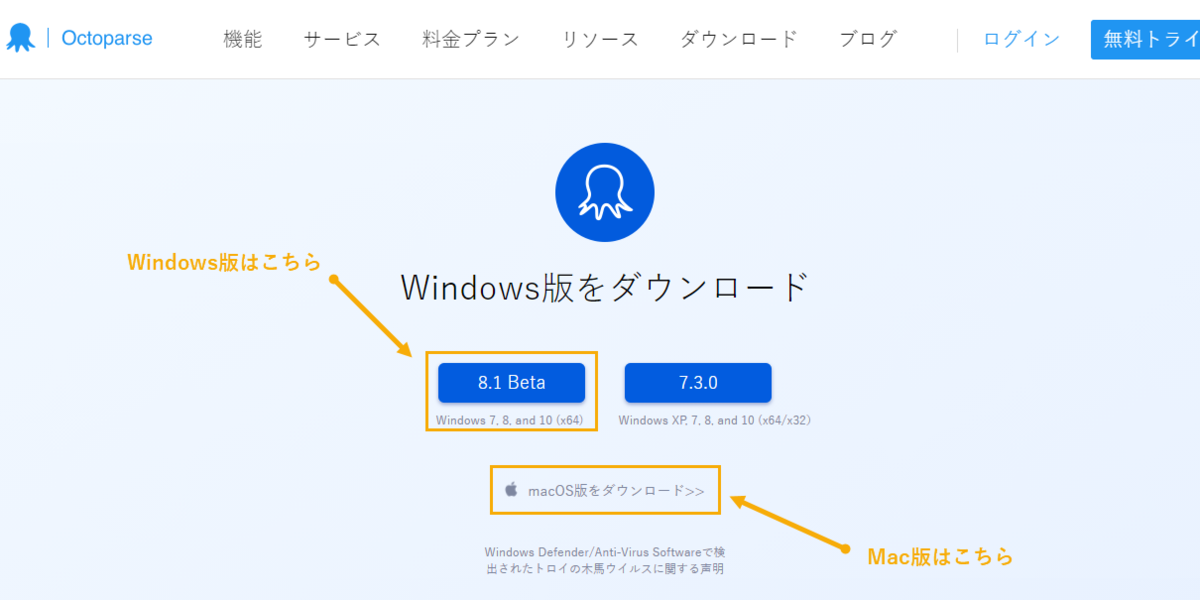
注:Octoparseは無料プランを提供しています。このガイドに記載されている機能にお金を払う必要はありません。
3. 2つのステップだけで、すべての画像URLを取得
ステップ1: タスクを作成する
1)Octoparseを起動します。スクレイピングしたいWebページのURLを入力します。「抽出開始」 ボタンをクリックして進みます。

もうすぐホワイトデーですので、今回は楽天市場上のチョコレートの画像を例にしてみましょう。
サンプルURL: https://search.rakuten.co.jp/search/mall/チョコレート/
(このリンクが無効になった場合は、楽天市場の別の検索結果のリンクを使ってください)
2)Octoparseでページが読み込みされたら、自動的にページ上の内容を識別します。もし自動識別機能をオフする場合は、右上の操作ヒントパネルで 「Webページを自動識別する」、ページ上の内容を識別します。自動識別とは、自動的にページ上の必要なデータを検出して識別するという役立つ機能です。ポイント&クリックをする必要はなく、Octoparseは自動的に処理します。

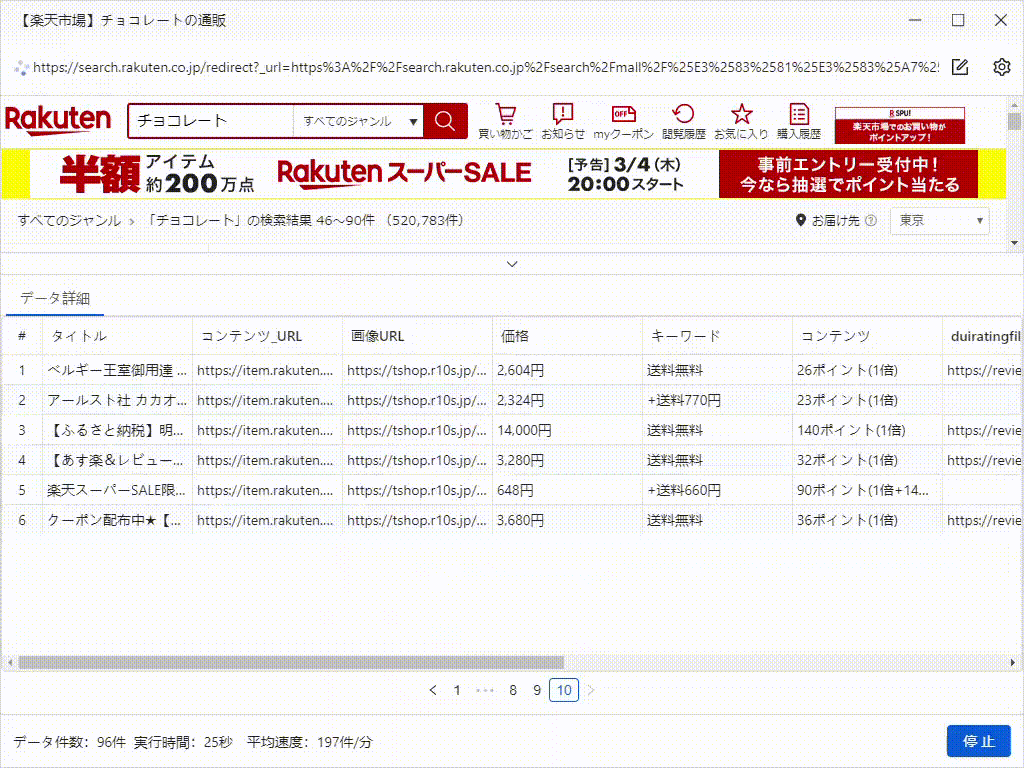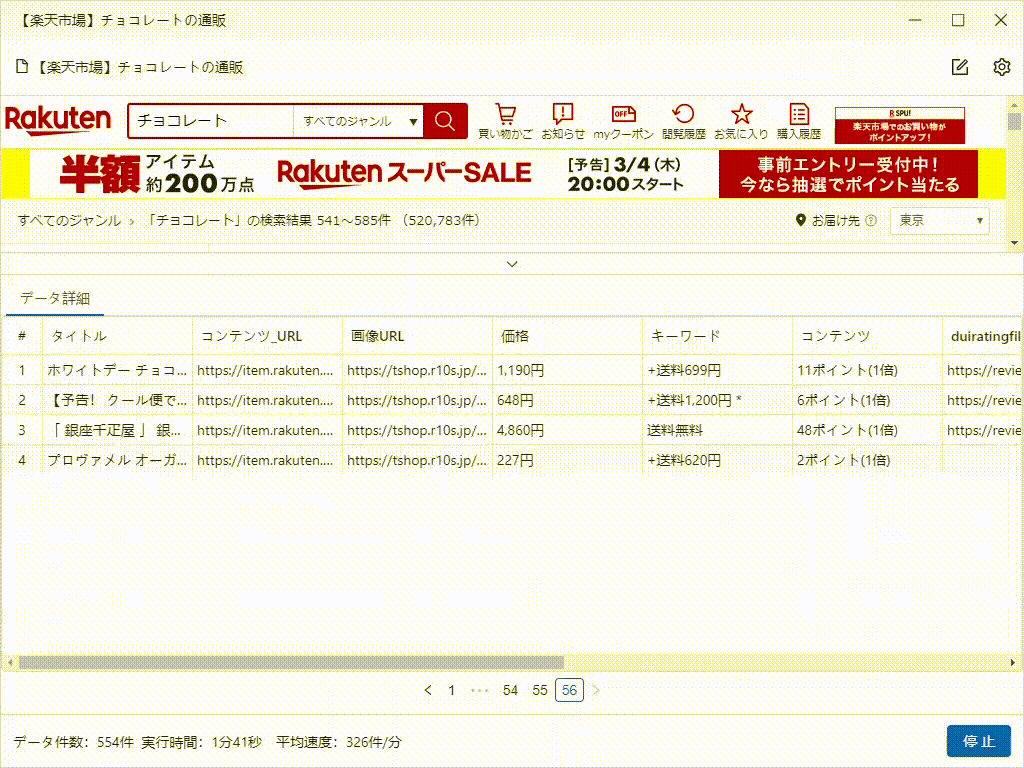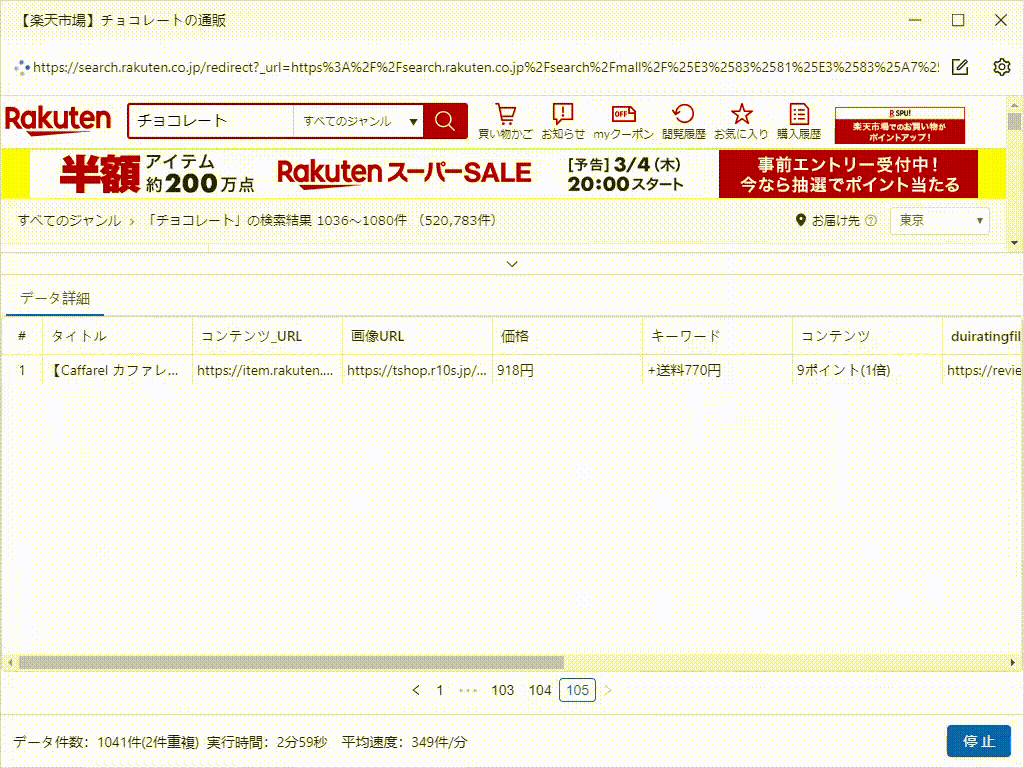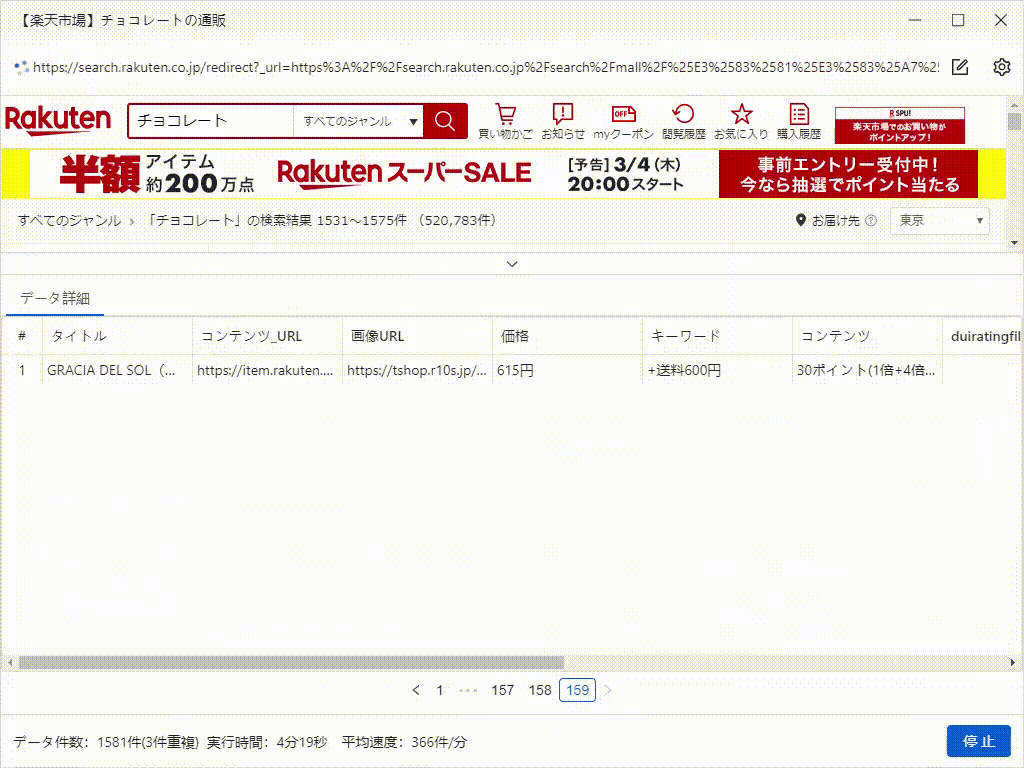
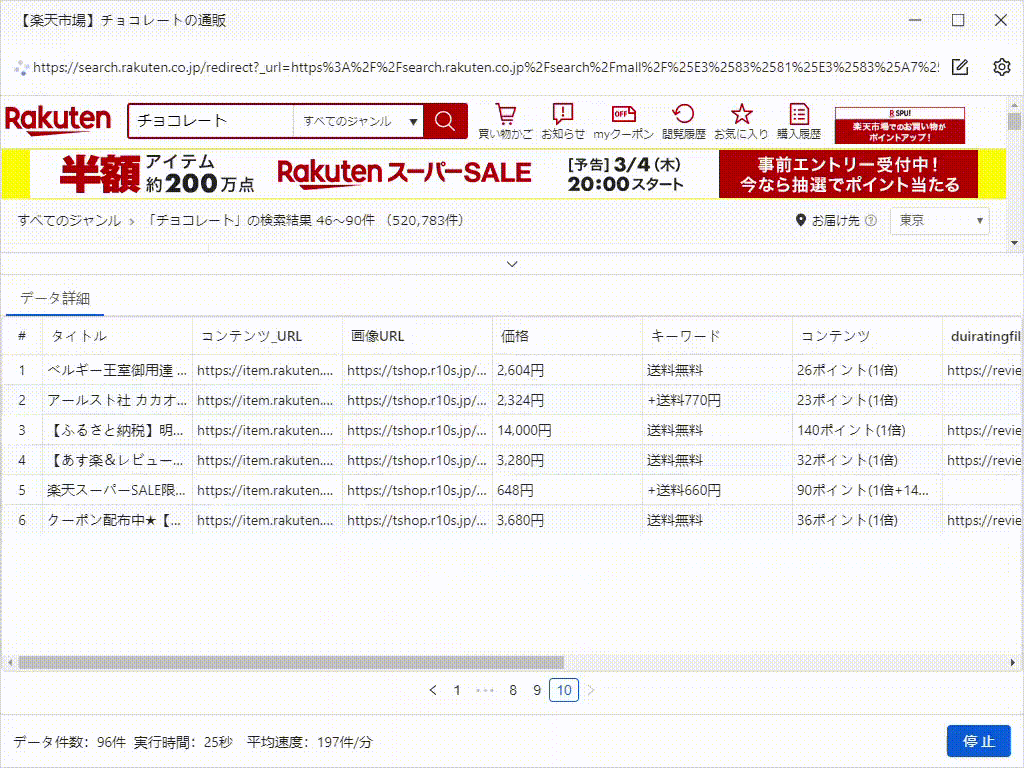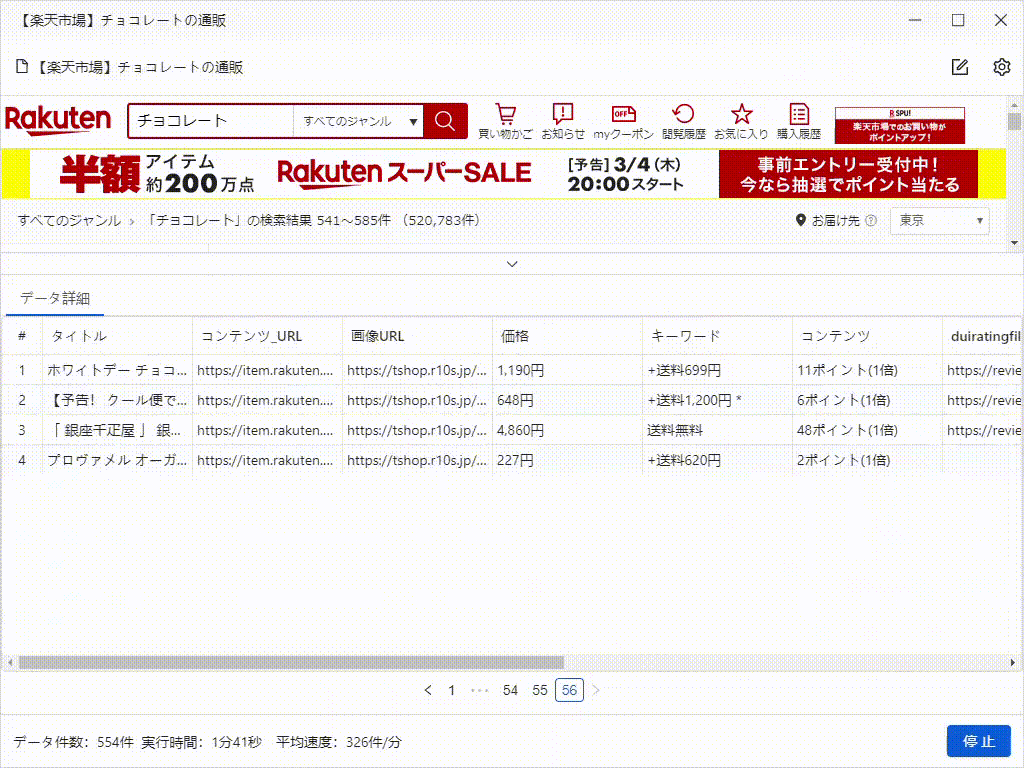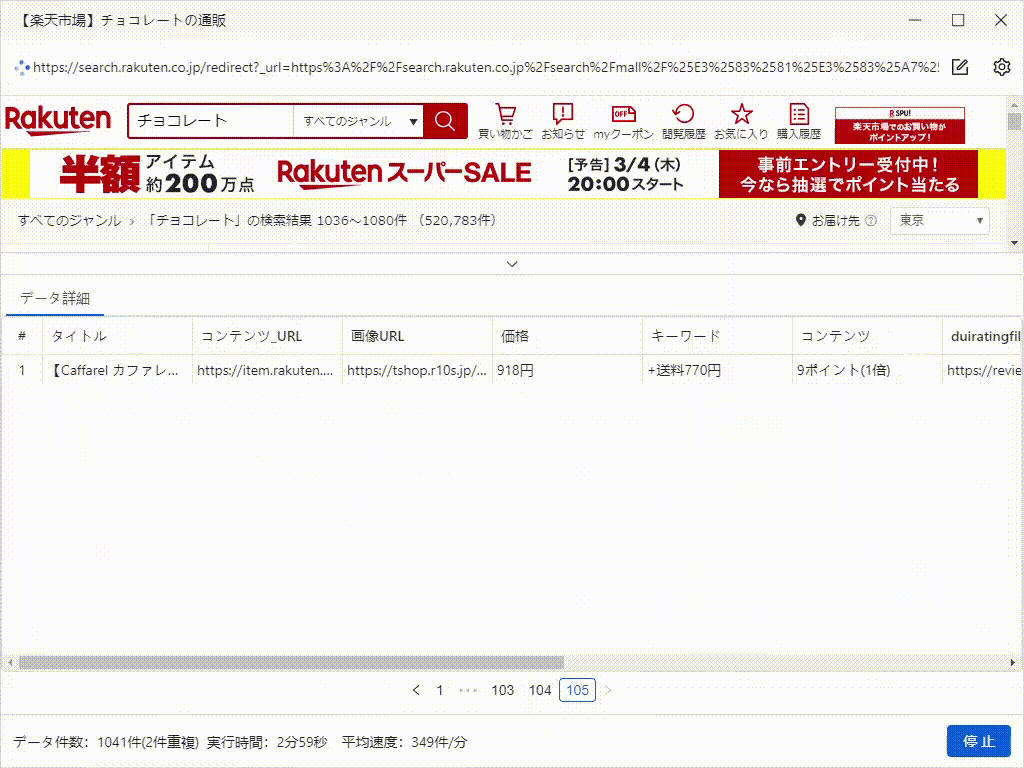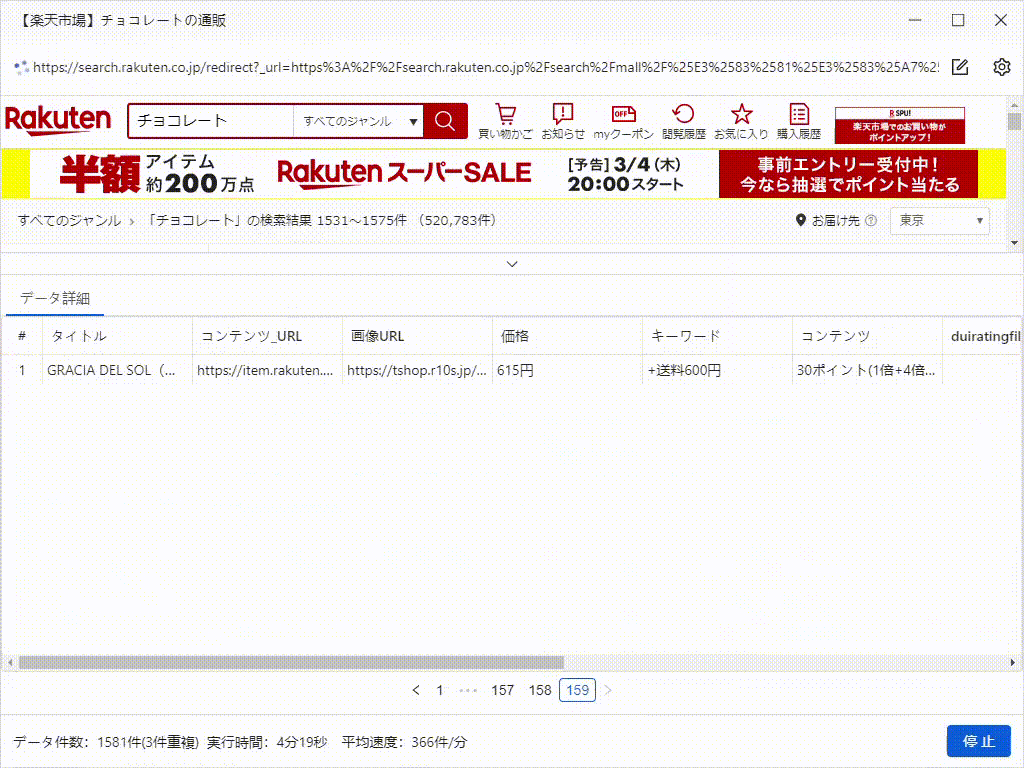
3)識別が完了すると、データプレビューで識別したデータを表示され、どのようなデータが取得されているかを確認することができます。「識別結果を切り替える」をクリックすると、ページの異なる場所の識別結果を指定することができます。「ワークフローを生成」をクリックして確認し、タスクを作成します。

ステップ2: タスクを実行する
上の「実行」ボタンをクリックして、すぐタスクを実行できます。たった数分で数千件のデータを取得することができます。これがOctoparseのスピードです。一度Octoparseのコツをつかめば、以前Webデータを取得するための手作業で時間を無駄にしていたことを後悔するに違いありません。

これは、たった5分で抽出したデータです。実際、それはすべての画像のURLだけでなく、製品の詳細ページのデータもスクレイピングできます。これは、競合調査やEC(Eコマース)分析をしている方には、非常に役立つツールです。
4. 数秒で画像を一括ダウンロード!
すべての画像URLをExcelファイルに保存した状態で、この動画から紹介された一括ダウンロードツールを使って、全ての画像をダウンロードします。今回はChromeの「Tab Save」という拡張機能を例として試していきましょう。

画像のURLをコピーしてタブ保存に貼り付け、ダウンロードをクリックすると、すべての画像が数秒でコンピュータにダウンロードされます。

全体のプロセスはわずか10分かかります。楽天市場から画像の数千(サイトに応じて具体的なデータ件数も変わります)をダウンロードできます。ぜひ試してみてください!
もしタスクは不具合な状況がある場合…
今回の例で自動識別による生成したタスクは問題なく実行できますが、もしタスクは不具合な状況がある場合は、どのように修正すればいいでしょうか?
1. ページネーションが無効の場合
このステップでは、ページネーションを確認し、必要に応じてXpathを修正していきます。ページネーションについてこちらでご参照ください。
具体的には、ステップ「ページネーション」をダブルクリックすると、設定画面が表示されます。その設定画面には、自動識別で作成されたXpathがあります。
・どのように修正すればいいでしょうか?
右側の小さな矢印をクリックして、右側の内蔵ブラウザで「次のページ」ボタンをクリックします。これはクローラーに「これが私がクリックしたいボタン」を指示しています。簡単でしょうね。

・もし上記の方法を修正してもダメな場合はどうすればいいでしょうか?
下記の画像の通りに、Xpathを入力してください。
(//a[@class="item -next nextPage"][contains(string(),"次のページ")][not(@disabled)])[1]

2. 画像が読み込まないの場合
ページが完全に読み込みされるため、スクロールダウンの設定が必要となります。このステップは、スクロールダウンを設定することです。Octoparseで数回のクリックするだけで設定できます!
ワークフローに戻って、「Webページを開く」をダブルクリックし、「Webページを読み込んだ後」で「スクロールダウン」にチェックを入れ、2秒間隔でスクロール1回、回数50回を設定します。

これでタスクの修正は完了です!
5. まとめ
- Octoparseは、無料プランも提供しているWebスクレイピングツールです。ノーコード技術を使うため、非エンジニアでもスクレイピングすることができます。Webスクレイピングプロジェクトを1から始める最適なツールです。
- Octoparseの自動識別機能を利用して、Webサイトから簡単にデータを取得することができます。これにより、他のツールでややこしいステップ設定から解放されます。
- 自動識別機能を利用して、Xpathを書く必要はありません!ポイント&クリックだけでテキストやボタンなどの内容を指定できます。これは最もやりやすい方法です。
参考記事:
画像を一括ダウンロードするのに超便利なツール5選
注目のWebスクレイピングツール5選を徹底比較!
ECサイトからデータを抽出する3つの課題
Webスクレイピングによる価格戦略・価格の決め方
【完全初心者向け】求人情報を一括で自動的に取得する方法公開!
元記事:https://www.octoparse.jp/blog/a-complete-guide-to-web-scraping-job-postings/
2020年以来、新型コロナウイルス感染症の感染拡大による景気低迷によって悪化に転じました。総務省が12月25日発表した11月の労働力調査によると、完全失業率は2.9%になりました。一方、厚生労働省が発表した8月の有効求人倍率は8カ月連続の低下となりました。
つまり、同倍率は仕事を探す人1人に対し、何件の求人があるかを示します。企業からの有効求人は前月から0.9%増えたものの、働く意欲のある有効求職者が4.7%増えました。統計によると、現在は求人に対して、求職者の数が上回っている状態です。
市場競争がますます激しくなっている不景気の中では、まだまだチャンスが残っています。そのチャンスは一歩先に有益な情報を手に入れた会社や人たちにあります。

企業側にとって、早めに求人情報を手に入れることは、
・仕事の傾向や労働市場に合わせて自社事業をを分析・調整できる
・競合他社の動向を追跡・分析できる
・営業リストを整理・作成できる
.......
個人側にとって、早めに求人情報を手に入れることは、
・仕事の傾向や労働市場を分析できる
・目指すべき方向を調整できる
・就職チャンスをつかめる
.......
だが、データ収集はそんなに簡単にできることではないですね。特に、初心者にとっては短時間内での実現がさらなる不可能です。それではどのように求人情報を取得すればよいでしょうか。
これからこの記事で3つの取得方法を紹介し、さらにそのメリットとデメリットも一緒にご参考いただければと思います。
方法一:自分でクローラーをセットアップする
簡単に言うと、ご自力でデータを取得するWebスクレイピングを作るということです。本記事ではプログラムを作る詳細を紹介しません。もしご興味があれば、こちらの記事をご参考いただきます。
参考記事:【Pythonクローラー入門】クローリング スクレイピング方法 総まとめ
メリット:
1) クローリングプロセスを完全にコントロールことができる
2) コミュニケーションの手間が少なく、迅速な対応が可能
デメリット:
1) 専門知識を勉強する時間が必要
Webスクレイピングは、高いレベルな技術が必要とする独特なプロセスであり、特に人気のあるWebサイトのいくつかからスクレイピングする必要がある場合や、定期的にデータを大量に抽出する必要がある場合です。
2) 配置・運用・保守の技術力が必要
Webサイトのレイアウトやコードが更新するたびに、常にクローラーを動かすようなメンテナンス時間と技術力が必要です。
方法二:データ代行収集サービス(DaaS)を依頼する
いわゆるお金を払ってデータ取得の作業を他の企業や個人などに依頼するということです。「餅は餅屋」という通り、何事においても、その道の専門家に任せるのが一番ですね。
一般的には、依頼する時にサイト数、それからサイトのHTML構造や取得するデータ量などによって料金が異なってきます。
メリット:
1) IT専門知識を学習する時間を省く
2) 事務負担及び収集時に発生するリスクを軽減
高度なセキュリティ環境であるデータセンター内にて、効率的かつ安全、正確にデータの収集を行うことができます。
デメリット:
1) 料金が比較的に高くなる
2) 依頼先とのコミュニケーションに時間がかかる
3) 依頼先にサイトの取得可能性を検証してもらい、発注してから納品までのセットアップ時間が長い
方法三: Webスクレイピングツールを使う
多くの人はまだ知らないと思いますが、実際にテクノロジーの進歩により、Webスクレイピングを自動化してくれるツールもあります。
完全な素人でも使えるようなWebスクレイピングツールはWebページのHTML構造を自動的に識別したり、必要なデータを自由に選択したり、自由にカスタマイズすることなどの機能が備えていています。もしご興味があれば、こちらの記事を見てみてください。
参考記事:無料で使えるスクレイピングツール9選
メリット:
1) コストが低い
2) 初心者にやさしい
3) 自由な時間に取得可能
4) カスタマイズ自由度が高い
5) 高度なカスタマイズが可能
6) 低メンテナンスコスト
デメリット:
1) プログラム作成ほどではないけど、操作設定を慣れる時間が必要
2) ベンダーさんのサーバー不安定による故障がよくある
前では求人情報を取得する3つの方法を紹介しましたが、これからは無料WebスクレイピングツールのOctoparseを使って、Indeedから「東京 エンジニア」の下記求人情報をスクレイピングできました。
Octoparseをインストールしてからの操作設定の詳細はここで紹介しませんので、興味のある方はこちらのチュートリアルを参考してください。

参考記事: